Guest post by Jonathan Rosenblatt
Disclaimer:
This post is not intended to be a comprehensive review, but more of a “getting started guide”. If I did not mention an important tool or package I apologize, and invite readers to contribute in the comments.
Introduction
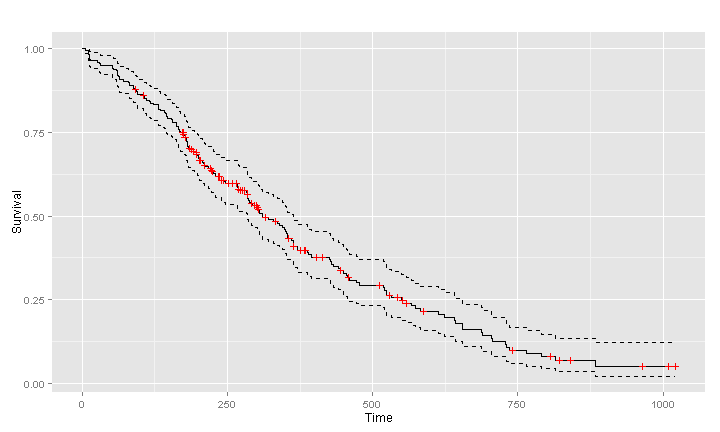
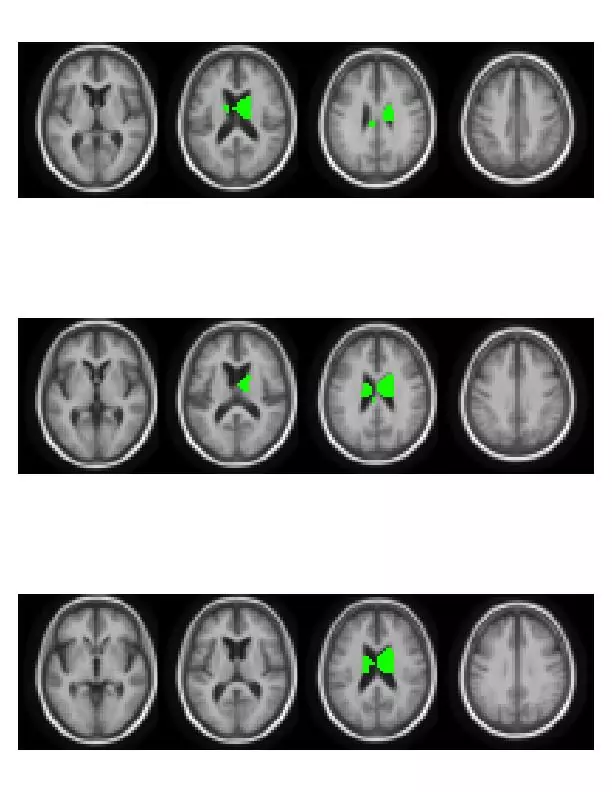
I have recently had the delight to participate in a “Brain Hackathon” organized as part of the OHBM2013 conference. Being supported by Amazon, the hackathon participants were provided with Amazon credit in order to promote the analysis using Amazon’s Web Services (AWS). We badly needed this computing power, as we had 14*109 p-values to compute in order to localize genetic associations in the brain leading to Figure 1.
| Figure 1- Brain volumes significantly associated to genotype. |
 |
While imaging genetics is an interesting research topic, and the hackathon was a great idea by itself, it is the AWS I wish to present in this post. Starting with the conclusion:
Storing your data and analyzing it on the cloud, be it AWS, Azure, Rackspace or others, is a quantum leap in analysis capabilities. I fell in love with my new cloud powers and I strongly recommend all statisticians and data scientists get friendly with these services. I will also note that if statisticians do not embrace these new-found powers, we should not be surprised if data analysis becomes synonymous with Machine Learning and not with Statistics (if you have no idea what I am talking about, read this excellent post by Larry Wasserman).
As motivation for analysis in the cloud consider:
- The ability to do your analysis from any device, be it a PC, tablet or even smartphone.
- The ability to instantaneously augment your CPU and memory to any imaginable configuration just by clicking a menu. Then scaling down to save costs once you are done.
- The ability to instantaneously switch between operating systems and system configurations.
- The ability to launch hundreds of machines creating your own cluster, parallelizing your massive job, and then shutting it down once done.
Here is a quick FAQ before going into the setup stages.
FAQ
Q: How does R fit in?
Continue reading “Analyzing Your Data on the AWS Cloud (with R)”