R 3.2.1 (codename “World-Famous Astronaut”) was released yesterday. You can get the latest binaries version from here. (or the .tar.gz source code from here). The full list of new features and bug fixes is provided below.
Upgrading to R 3.2.1 on Windows
If you are using Windows you can easily upgrade to the latest version of R using the installr package. Simply run the following code in Rgui:
install.packages("installr") # install
installr::updateR() # updating R.
I try to keep the installr package updated and useful, so if you have any suggestions or remarks on the package – you are invited to open an issue in the github page.
CHANGES IN R 3.2.1:
NEW FEATURES
utf8ToInt() now checks that its input is valid UTF-8 and returns NA if it is not.
install.packages() now allows type = "both" with repos = NULL if it can infer the type of file.
nchar(x, *) and nzchar(x) gain a new argument keepNA which governs how the result for NAs in x is determined. For the R 3.2.x series, the default remains FALSE which is fully back compatible. From R 3.3.0, the default will change to keepNA = NA and you are advised to consider this for code portability.
news() more flexibly extracts dates from package ‘NEWS.Rd’ files.
lengths(x) now also works (trivially) for atomic x and hence can be used more generally as an efficient replacement of sapply(x, length) and similar.
The included version of PCRE has been updated to 8.37, a bug-fix release.
diag() no longer duplicates a matrix when extracting its diagonal.
as.character.srcref() gains an argument to allow characters corresponding to a range of source references to be extracted.
If you are running R on Windows you can easily upgrade to the latest version of R using the installr package. Simply run the following code:
# installing/loading the latest installr package:
install.packages("installr"); library(installr) # install+load installr
updateR() # updating R.
Running “updateR()” will detect if there is a new R version available, and if so it will download+install it (etc.). just press “next”, “OK”, and “Yes” on everything…
A GUI interface to updating R on Windows
Starting from installr version 0.15.0, the upgradingprocess can be done with a click-on-menus GUI interface. Here is how to use it.
R 3.2.0 (codename “Full of Ingredients”) was released yesterday. You can get the latest binaries version from here. (or the .tar.gz source code from here). The full list of new features and bug fixes is provided below.
Upgrading to R 3.2.0 on Windows
If you are using Windows you can easily upgrade to the latest version of R using the installr package. Simply run the following code:
# installing/loading the latest installr package:
install.packages("installr"); library(installr) #load / install+load installr
updateR() # updating R.
Running “updateR()” will detect if there is a new R version available, and if so it will download+install it (etc.).
I try to keep the installr package updated and useful, so if you have any suggestions or remarks on the package – you are invited to leave a comment below.
CHANGES IN R 3.2.0:
As always, David smith mentioned in his post some of the main changes, writing how many of the changes in this release have happened behind the scenes to improve R’s engine for performance and reliability. These include:
A number of fixes proposed by Radford Neal, bringing some of the performance improvements of pqR to R while maintaining backwards compatibility.
more progress in handling big in-memory data objects (for example, you can now cbind/rbind matrices with more than 2 billion elements).
some significant updates to R’s byte compiler with new instructions that allow many scalar subsetting and assignment and scalar arithmetic operations to be handled more efficiently. This can result in significant performance improvements in scalar numerical code.
the package-checking system now does a more thorough job of making sure contributed packages comply with CRAN policies.
And here is also the full list of new features, bug fixes, etc:
(This is a guest post by my friend Yoni Sidi, a PhD candidate in statistics at the Hebrew University)
Background
The Israeli elections are coming up this Tuesday, 17/3/2015 (i.e.: tomorrow!). They are a bit more complicated than your average US presidential race. The elections in Israel are based on nationwide proportional representation. The electoral threshold is 3.25% and the number of seats (or mandates) out of a total of 120 is proportional to the number of votes it recieves, so the threshold roughly translates to at least four mandates. The Israeli system is a multi-party system and is based on coalition governments. Multi-party is putting it mildly, there are 11 that have a chance (and are expected) to pass the mandate threshold.
There are two major parties, Hamachane Hazioni (Left Wing) and the Likud (Right Wing), that are hoping to garner between 16%-25% of the votes, 20-30 mandates. The main winners though are the medium size parties that recomend to the President who they think has the best chance to construct the next government, so yes there is a good possibility that the general elections winner will not be one constructing the coalition. Making the actual winners the parties that create the biggest coalition which exceeds 60 mandates.
An abundance of polling has been continually published during the run up and the variaety of pollsters and publishers is hard to keep track of as a casual voter trying to gauge the temperature of the political landscape. I came across a great realtime database by Project 61 on google docs of past and present polling result information and decided that it was a great opportunity to learn the Shiny library of RStudio and create an app that I can check current and past results. So after I figured out how to connect google docs to R, I created a self updating app that became a nice place to keep track of polling every day, check trends and distributions using interactive ggplot2 graphs and simulate coalition outcomes.
Please note that as of Friday (March 13th), until election day (March 17th), it is forbidden to perform new polls in Israel, hence the data presented here cannot allow for an up-to-date inference about the expected results of the election. This post is for educational purposes.
Running the election polls Shiny app on your computer
#changing locale to run on Windows
if (Sys.info()[1] == "Windows") Sys.setlocale("LC_ALL","Hebrew_Israel.1255")
#check to see if libraries need to be installed
libs <- c("shiny","shinyAce","httr","XML","stringr","ggplot2","scales","plyr","reshape2","dplyr")
x <- sapply(libs,function(x)if(!require(x,character.only = T)) install.packages(x))
rm(x,libs)
#run App
shiny::runGitHub("Elections","yonicd",subdir="shiny")
#reset to original locale on Windows
if (Sys.info()[1] == "Windows") Sys.setlocale("LC_ALL")
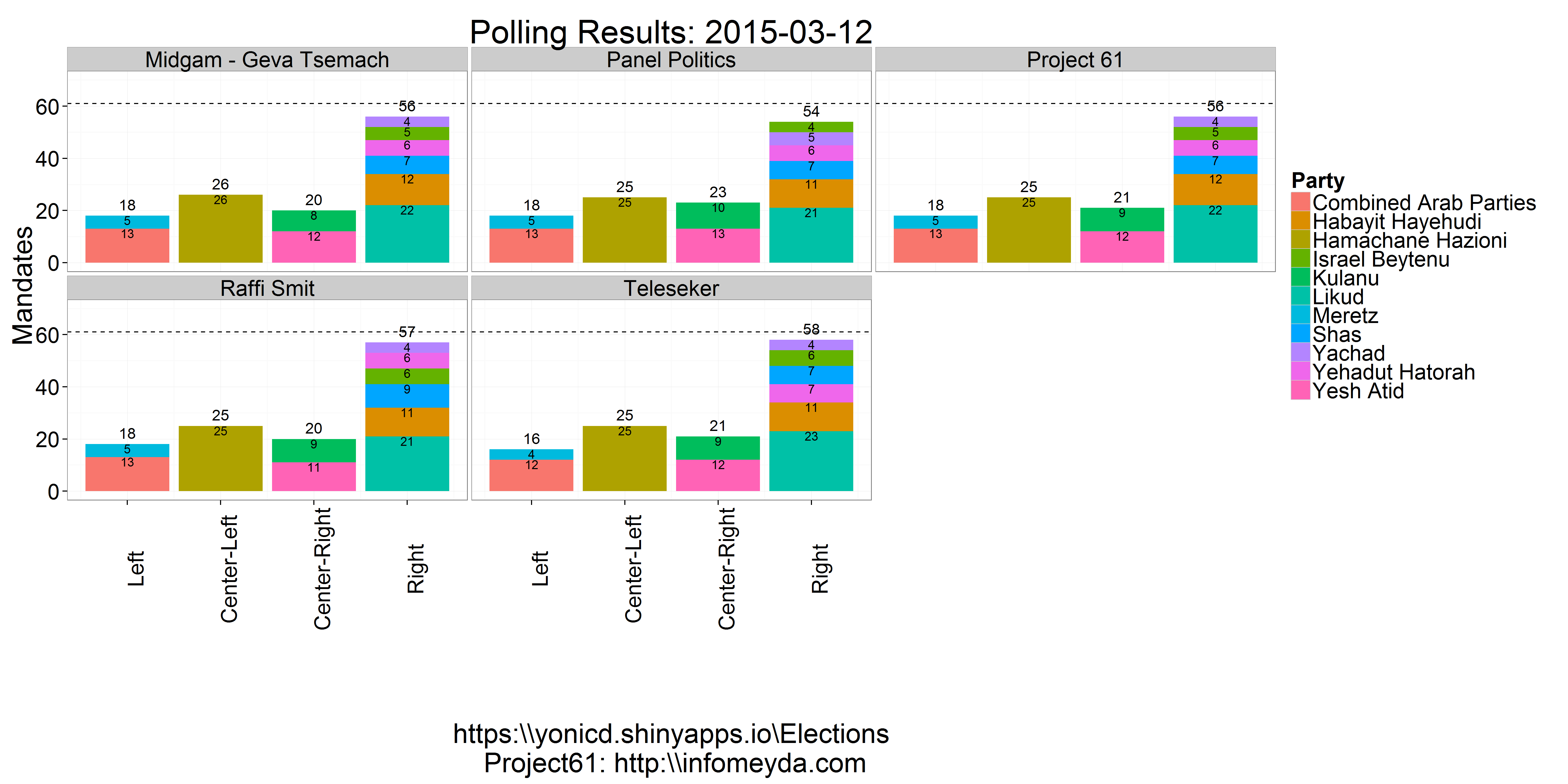
The latest polling day results published in the media and the prediction made using the Project 61 weighting schemes. The parties are stacked into blocks to see which block has best chance to create a coalition.
The Project 61 prediction is based past pollster error deriving weights from the 2003,2006,2009 and 2013 elections, dependant on days to elections and parties. In their site there is an extensive analysis on pollster bias towards certain parties and party blocks.
Election Analysis
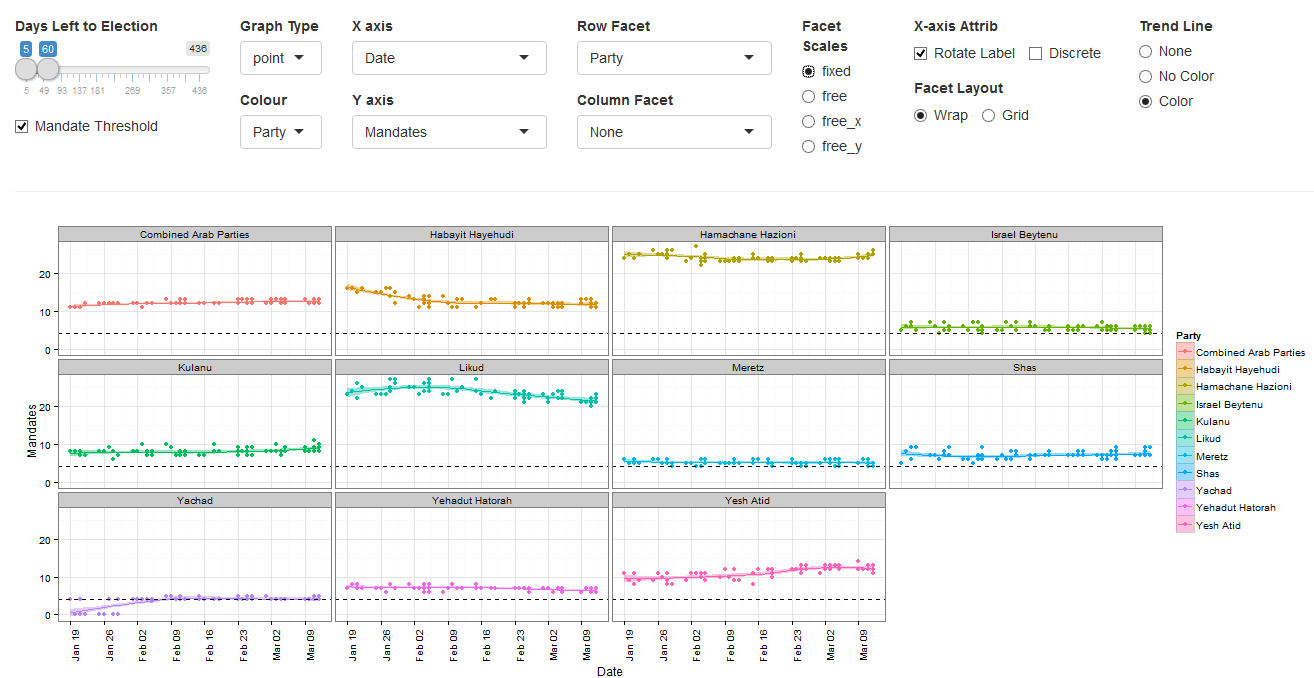
An interactive polling analysis layout where the user can filter elections, parties, publishers and pollster, dates and create different types of plots using any variable as the x and y axis.
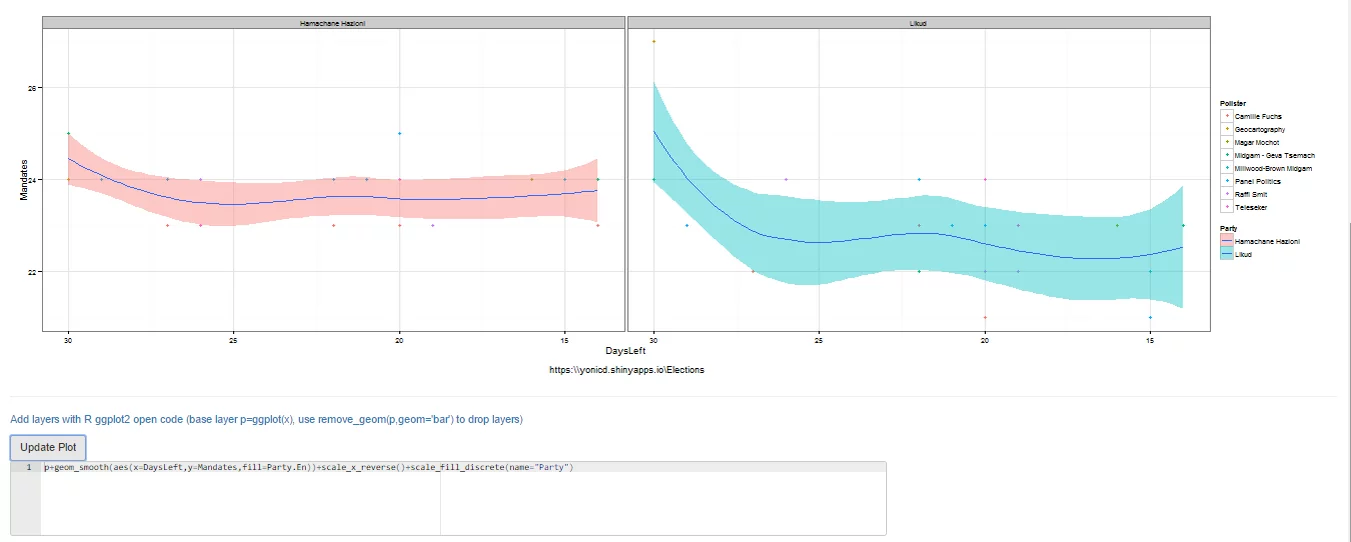
The default layer is the 60 day trend (estimated with loess smoother) of mandates published by each pollster by party
The user can choose to include in the plots Elections (2003,2006,2009,2013,2015) and the subsequent filters are populated with the relevant parties, pollsters and publishers relevant to the chosen elections. Next there is a slider to choose the days before the election you want to view in the plot. This was used instead of a calendar to make a uniform timeline when comparing across elections.
In addition the plot itself is a ggplot thus the options above the graph give the user control on nearly all the options to build a plot. The user can choose from the following variables:
Time
Party
Results
Poll
Election
Party
Mandates
Publisher
DaysLeft
Ideology (5 Party Blocks)
Mandate.Group
Pollster
Date
Ideology.Group (2 Party Blocks)
Results
year
Attribute (Party History)
(Pollster) Error
month
week
To define the following plot attributes:
Plot Type
Axes
Grouping
Plot Facets
Point
X axis variable
Split Y by colors using a different variable
Row Facet
Bar
Discrete/Continuous
Column Facet
Line
Rotation of X tick labels
Step
Y axis variable
Boxplot
Density
Create Facets to display subsets of the data in different panels (two more variables to cut data) there are two type of facets to choose from
Wrap: Wrap 1d ribbon of panels into 2d
Grid: Layout panels in a grid (matrix)
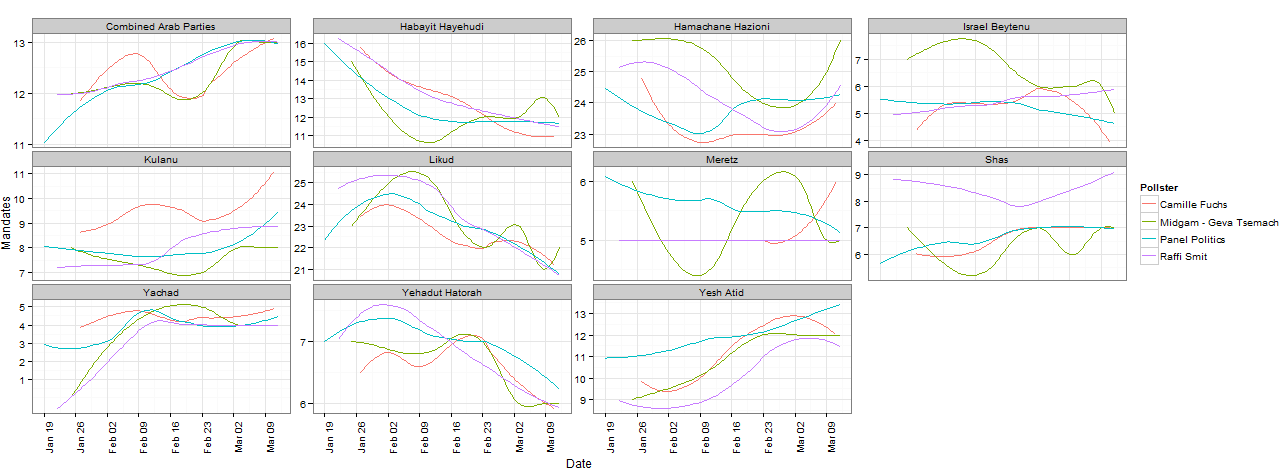
An example of filtering pollsters to compare different tendencies for each party in the 2015 elections:
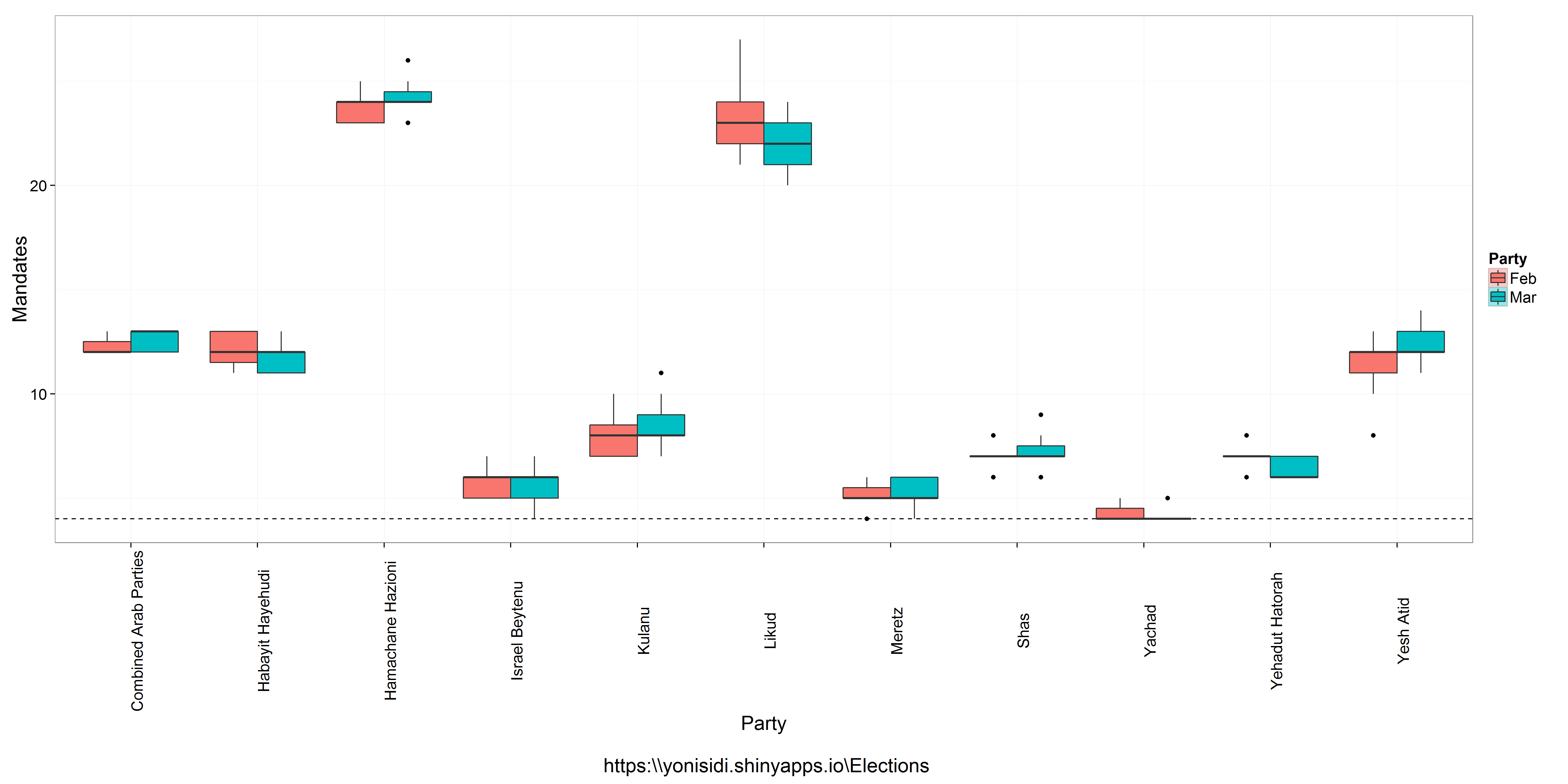
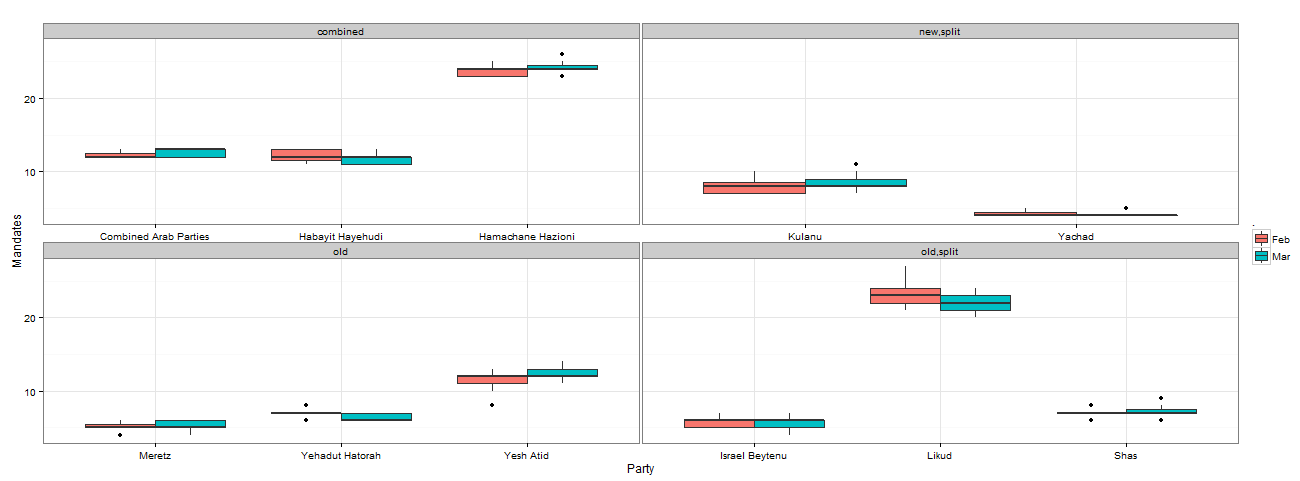
An example of comparing distribution mandates per party in the last two months of polling
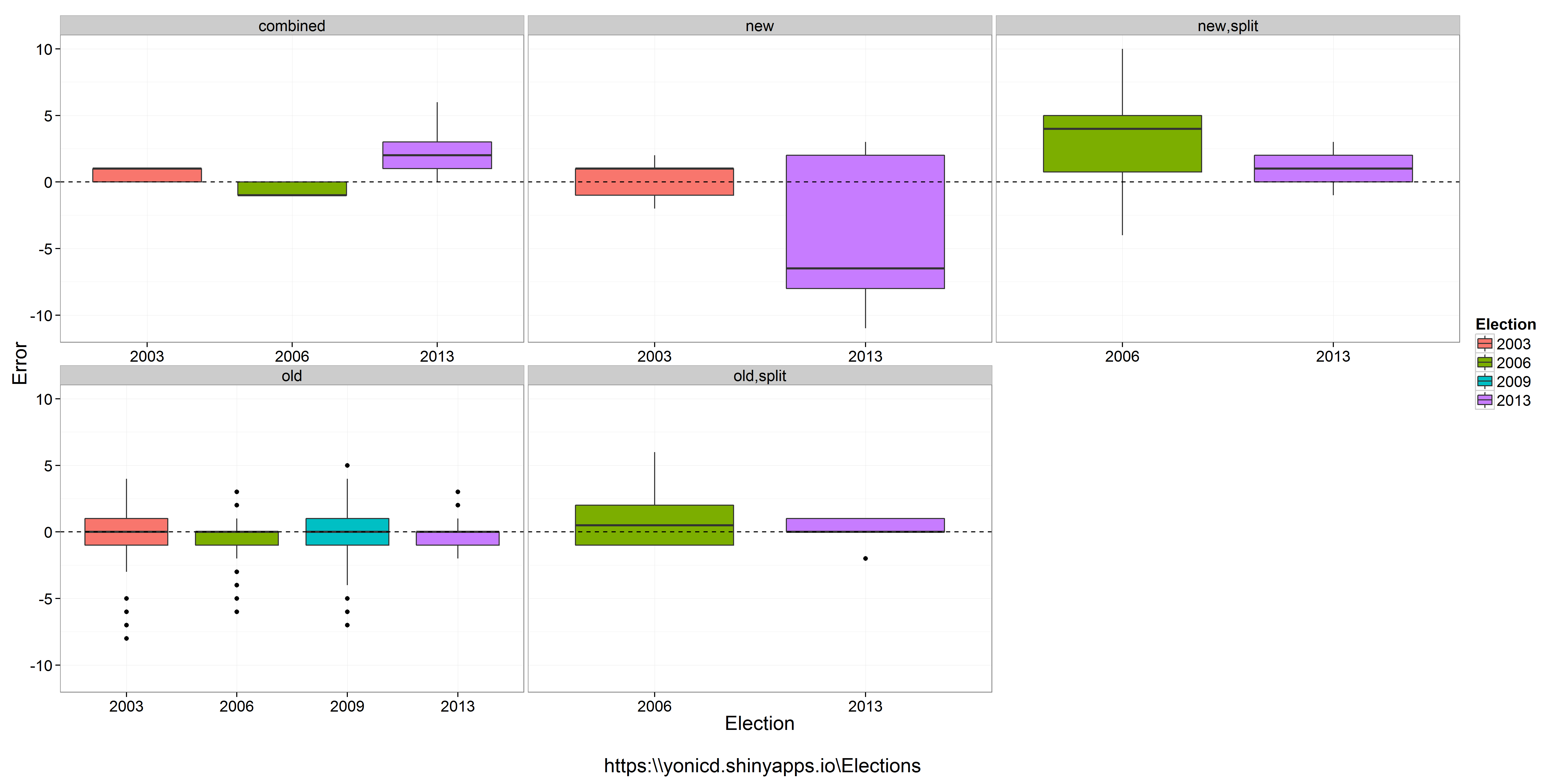
An example of comparing distribution of pollster errors across elections (up to 10 days prior end of polling), by splitting the parties into five groups compared to previous election: old party,new party, combined (combination of two or more old parties), new.split (new party created from a split of a party from last election), old.split (old party that was a left from the split).
As we can see the pollster do not get a good indication of new,new.split or combined parties, which could be a problem this election since there are: 3 combined, 2 new splits.
If you are an R user and know ggplot there is an additional editor console,below the plot, where you can create advanced plots freehand, just add to the final object from the GUI called p and the data.frame is x, eg p+geom_point(). Just notice that all aesthetics must be given they are not defined in the original ggplot() definition. It is also possible to use any library you want just add it to the top of the code, the end object must be a ggplot.
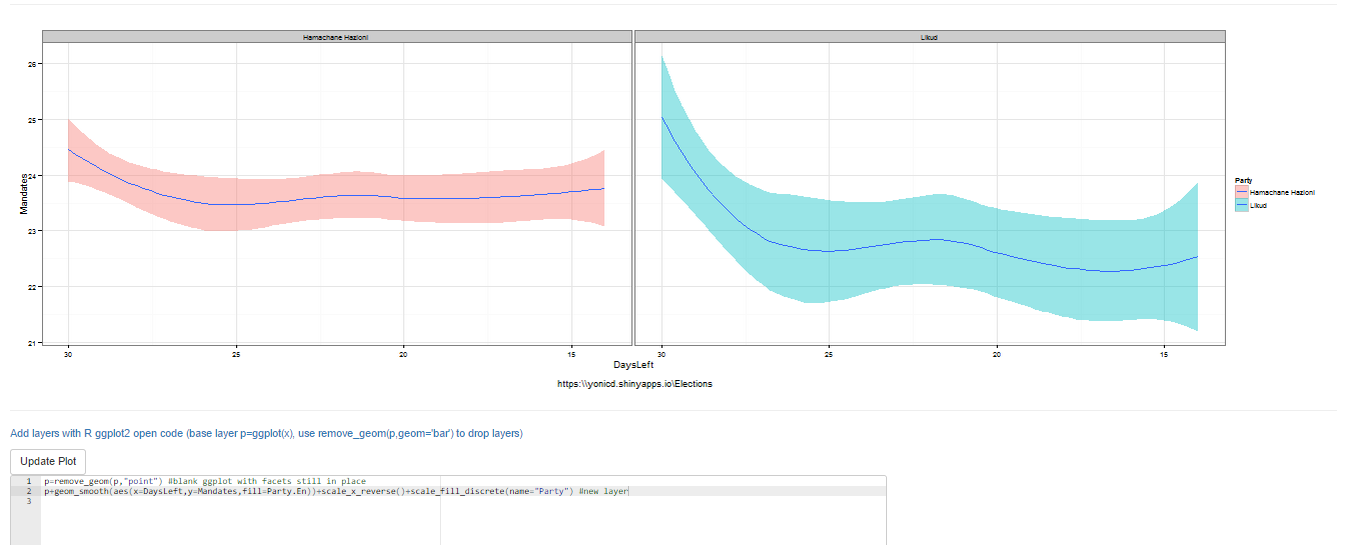
You can also remove the original layer if you want using the function remove_geom(ggplot_object,geom_layer), eg p=p+remove_geom(p,“point”) will remove the geom_point layer in the original graph
p=remove_geom(p,"point")#blank ggplot with facets in place#new layerp+geom_smooth(aes(x=DaysLeft,y=Mandates,fill=Party.En))+scale_x_reverse()+scale_fill_discrete(name="Party")
Finally the plots can be viewed in English or Hebrew, and can be downloaded to you local computer using the download button.
Mandate Simulator and Coalition Whiteboard
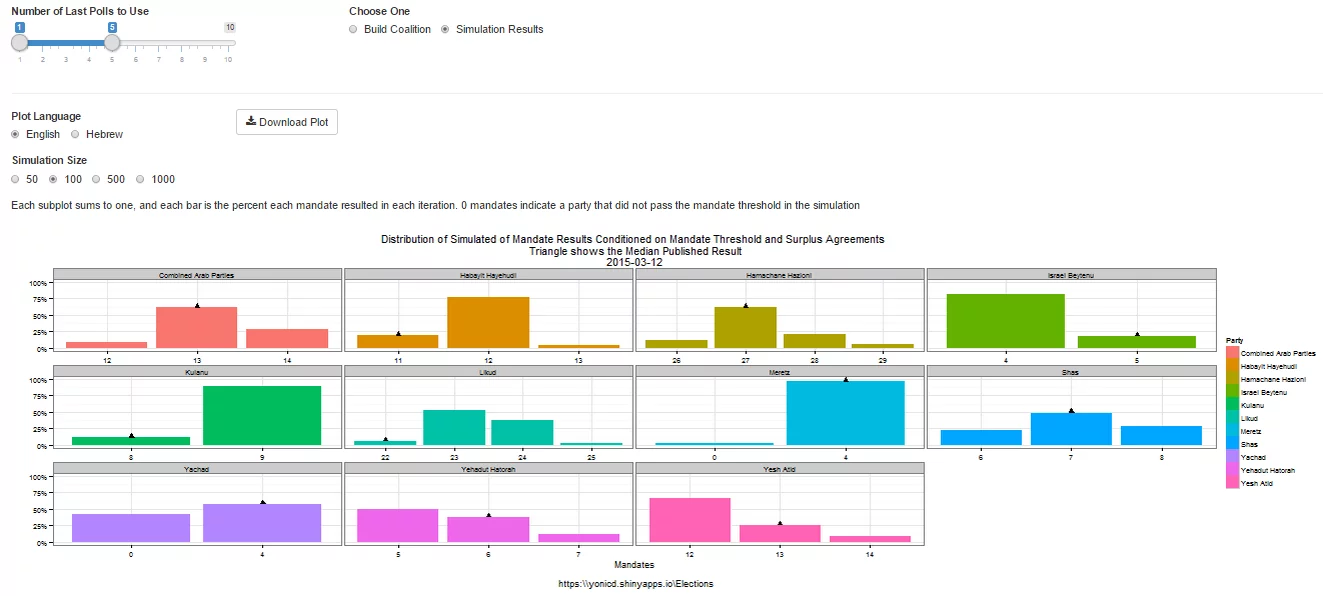
A bootstrap simulation is run on Polling results from up to 10 of the latest polls using the sampling error as the uncertainty of each mandate published. Taking into account mandate surplus agreements using the Hagenbach-Bischoff quota method and the mandate threshold limit (in this election it is 4 mandates), calculating the simulated final tally of mandates. The distributions are plotted per party and the location of the median published results in the media.
The user can choose how many polls to take into account, up to last 10 polls, and how big a simulation they want to run: 50,100,500,1000 random polling results per each party and poll.
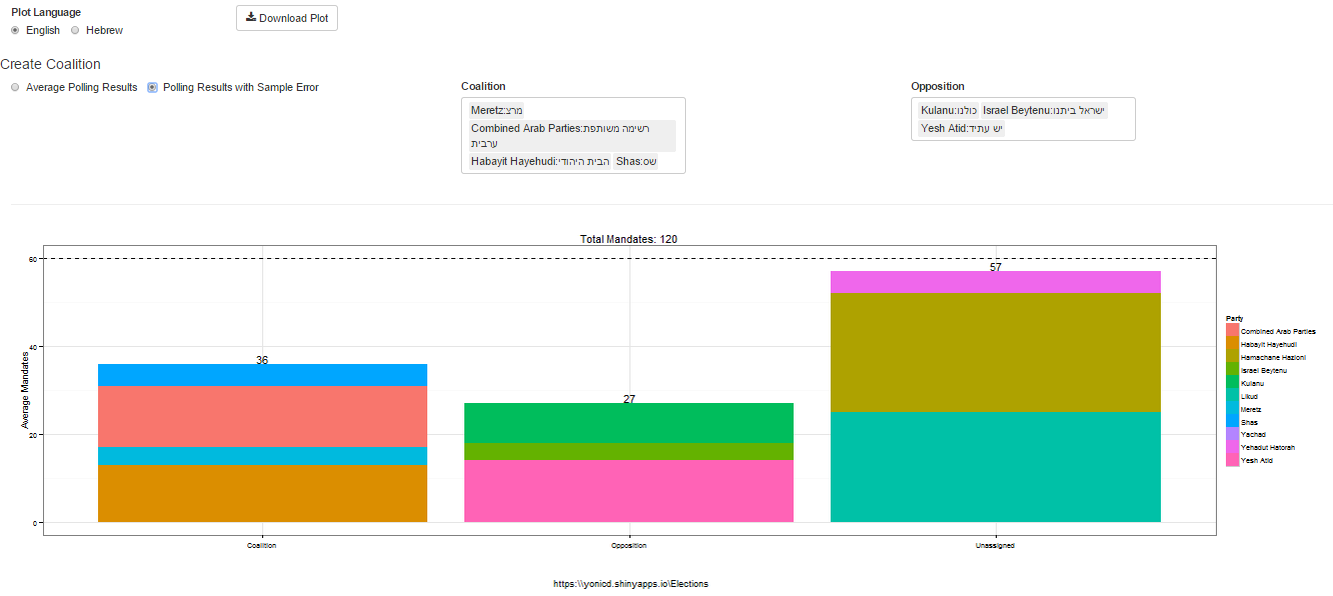
Once the simulator is complete you can create coalitions based on either the simulated distribution or actual published polls and see who can pass 60 mandates. Choose the coalition parties and the opposition parties from dropdown lists. (Yes the ones chosen are nonsensical on purpose…)
Polling Database
All raw data used in the application can be viewed and filtered in a datatable.
R 3.1.3 (codename “Smooth Sidewalk”) was released today. You can get the latest binaries version from here. (or the .tar.gz source code from here). The full list of new features and bug fixes is provided below.
Upgrading to R 3.1.3 on Windows
If you are using Windows you can easily upgrade to the latest version of R using the installr package. Simply run the following code:
# installing/loading the latest installr package:
install.packages("installr"); library(installr) #load / install+load installr
updateR() # updating R.
Running “updateR()” will detect if there is a new R version available, and if so it will download+install it (etc.).
I try to keep the installr package updated and useful, so if you have any suggestions or remarks on the package – you are invited to leave a comment below.
As has become usual in March, this release is primarily for minor bugs and improvements in R, as the development switches focus to the next major release (R 3.2.0 is expected on April 16). Improvements include: ability to download files greater than 2GB on 32-bit builds; better handling of complex (imaginary) numbers for several functions; improved command completion in the Windows GUI; and improved performance when using S4 classes. (See the complete list here.)
If you use R in a production environment, you have most likely experienced that some circumstances change in ways that will make your R scripts run into trouble. Many things can go wrong; package updates, external data sources, daylight savings time, etc. There is a general increasing focus on this within the R community and words like “reproducibility”, “portability” and “unit testing” are buzzing big time. Many really neat solutions are already helping a lot: RStudio’s Packrat project, Revolution Analytic’s “snapshot” feaure, and Hadley Wickham’s testthat package to name a few. Another interesting package under development is Edwin de Jonge’s “validate” package.
I found myself running into quite a few annoying “runtime” moments, where some typically external factors break R software, and more often than not I spent just too much time tracking down where the bug originated. It made me think about how best to ensure that vulnarable statements behaves as expected and how to know exactly where and when things go wrong. My coding style is heaviliy influenced by the magrittr package’s pipe operator, and I am very happy with the workflow it generates:
It’s like a recipe. But the problem is that I found no existing way of tagging potentially vulnarable steps in the above process, leaving the choice of doing nothing, or breaking it up. So I decided to make “ensurer”, so I could do:
Now, I don’t have a blog, but Tal Galili has been so kind to accept the ensurer vignette as a post for r-bloggers.com. I hope that ensurer can help you write better and safer code; I know it has helped me. It has some pretty neat features, so read on and see if you agree!
This is a guest post by Stefan Milton, the author of the magrittr package which introduces the %>% operator to R programming.
Preface (by Tal Galili)
I was first introduced to the %>% (a.k.a: pipe) operator in R, thanks to Hadley Wickham’s (fascinating) dplyr tutorial (link to the workshop’s material) at useR!2014. After several discussions during the conference (including one very influential conversation with Rstudio’s Joe Cheng), I got convinced that the pipe operator is one (if not THE) mostimportantinnovation introduced, this year, to the R ecosystem.
Soon after, I contacted Stefan Milton (the author of the magrittr package), asking him to write about his implementation of the pipe operator. Stefan generously agreed, and what follows is what he had to share with the rest of us.
magrittr: The Difficult Crossing – by Stefan Milton Bache
It has only been 7 months and a bit since my initial magrittr commit to GitHub on January 1st. It has had more success than I had anticipated, and it appears that I was not quite alone with a frustration which caused me to start the magrittr project. I am not easily frustrated with R, but after a few weeks working with F# at work, I felt it upon returning to R: I had gotten used to writing code in a different way — all nicely aligned with thought and order of execution. The forward pipe operator |> was so addictive that being unable to do something similar in R was more than mildly irritating. Reversing thought, deciphering nested function calls, and making excessive use of temporary variables almost became deal breakers! Surprisingly, I had never really noticed this before, but once I did my returning to R became a difficult crossing.
An amazing thing about R is that it is a very flexible language and the problem could be solved. The |> operator in F# is indeed very simple: it is defined as let (|>) x f = f x. However, the usefulness of this simplicity relies heavily on a concept that is not available in R: partial application. Furthermore, functions in F# almost always adhere to certain design principles which make the simple definition sufficient. Suppose that f is a function of two arguments, then in F# you may apply f to only the first argument and obtain a new function as the result — a function of the second argument alone. This is partial application, and works with any number of arguments, but application is always from left to right in the argument list. This is why the most important argument (and the one most likely to be a left-hand side object in the pipeline) is almost always the last argument, which in turn makes the simple definition of |> work. To illustrate, consider the following example:
some_value |> some_function other_value
Here, some_function is partially applied to other_value, creating a new function of a single argument, and by the simple definition of |>, this is applied to some_value.
It was clear to me that because R is lacking native partial application and conventions on argument order, no simple solution would be satisfactory, although definitely possible, see e.g. here or here. I wanted to make something that would feel natural in R, and which would serve the main purpose of improving cognitive performance of those writing the code, and of those reading the code.
It turned out that while I was working on magrittr’s %>% operator, Hadley Wickham and Romain Francois was implementing a similar %.% operator in their dplyr package which they announced on January 17. However, it was not quite as flexible, and we thought that piping functionality was better placed in its own more light-weight package. Hadley joined the magrittr project, and in dplyr 2.0 the %.% operator was deprecated — instead%>% was imported from magrittr.
R 3.1.1 (codename “Sock it to Me“) was released today! You can get the latest binaries version from here. (or the .tar.gz source code from here). The full list of new features and bug fixes is provided below.
Upgrading to R 3.1.1 on Windows
If you are using Windows you can easily upgrade to the latest version of R using the installr package. Simply run the following code:
After running “updateR()”, the function will detect that R is available for you, and will download+install it (etc.).
Note that the latest installr version (0.15.3) was released just less than a month ago to CRAN, and it is recommended to upgrade to it, since it has more updated URLs to some software. I try to keep the installr package updated and useful, so if you have any suggestions or remarks on the package – you are invited to leave a comment below.
If you use the global library system (as I do), you can run the following in the new version of R:
If you are using Windows, it might take another 24 hours until you could update R. For convenience, you can upgrade to the latest version of R using the installr package. Simply run the following code:
After running “updateR()”, the function will detect that R is available for you, and will download+install it (etc.).
Note that the latest installr version (0.14.0) was released a week ago to CRAN, and it is recommended to upgrade to it, since it is now more robust for various extreme cases of upgrading R. I try to keep the installr package updated and useful, so if you have any suggestions or remarks on the package – you are invited to leave a comment below.
If you use the global library system (as I do), you can run the following in the new version of R:
I am happy to officially announce a new website called R-users.com. The idea of the site is that community members will invite other R users to join them in their R projects, conferences, and work places.
This site is a “job board” for R users, hosting various “call to action” to R-users, to do stuff such as:
For example, I am the author of the R package “installr” for easily updating R on windows. However, I would love for someone who is a mac/linux user to expend my package for non-Windows users. Hence, I created a new “job”, inviting help on this project, which you may see in this link.
If you also wish to post your own “R job” for other R-users to see, here is a very short presentation on how to do it:
I intend to promote this site on r-bloggers.com, please help me in promoting this site on facebook and your own websites – so that more of us will be able to work together.