(Guest post by Matt Sundquist on a lovely new service which is pro-actively supporting an API for R)
The Plotly R graphing library allows you to create and share interactive, publication-quality plots in your browser. Plotly is also built for working together, and makes it easy to post graphs and data publicly with a URL or privately to collaborators.
In this post, we’ll demo Plotly, make three graphs, and explain sharing. As we’re quite new and still in our beta, your help, feedback, and suggestions go a long way and are appreciated. We’re especially grateful for Tal’s help and the chance to post.
>library(plotly)
>response = signup (username = 'username', email= 'youremail')
…
Thanks for signing up to plotly!
Your username is: MattSundquist
Your temporary password is: pw. You use this to log into your plotly account at https://plot.ly/plot. Your API key is: “API_Key”. You use this to access your plotly account through the API.
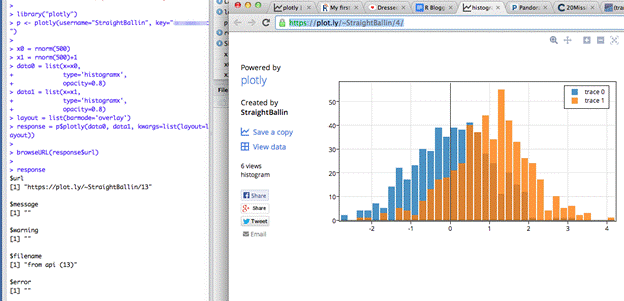
To get started, initialize a plotly object with your username and api_key, e.g.
>>> p <- plotly(username="MattSundquist", key="API_Key")
Then, make a graph!
>>> res <- p$plotly(c(1,2,3), c(4,2,1))
And we’re up and running! You can change and access your password and key in your homepage.
The script makes a graph. Use the RStudio viewer or add “browseURL(response$url)” to your script to avoid copy and paste routines of your URL and open the graph directly.
Various other enhancements (I like the new code folding for markdown headings/sections) and bug-fixes. Follow THIS LINK for a complete list of new features in this recent RStudio release.
Upgrading to R 3.0.2
You can download the latest version from here. Or, if you are using Windows, you can upgrade to the latest version using the installr package (also available on CRAN and github). Simply run the following code:
# installing/loading the package:
if(!require(installr)) {
install.packages("installr"); require(installr)} #load / install+load installr
updateR(to_checkMD5sums = FALSE) # the use of to_checkMD5sums is because of a slight bug in the MD5 file on R 3.0.2. This issue is already resolved in the installr version on github, and will be released into CRAN in about a month from now..
I try to keep the installr package updated and useful. If you have any suggestions or remarks on the package, you’re invited to leave a comment below.
If you use the global library system (as I do), you can run the following in the new version of R:
For a recent project I needed to make a simple sum calculation on a rather large data frame (0.8 GB, 4+ million rows, and ~80,000 groups). As an avid user of Hadley Wickham’s packages, my first thought was to use plyr. However, the job took plyr roughly 13 hours to complete.
plyr is extremely efficient and user friendly for most problems, so it was clear to me that I was using it for something it wasn’t meant to do, but I didn’t know of any alternative screwdrivers to use.
I asked for some help on the manipulator Google group , and their feedback led me to data.table and dplyr, a new, and still in progress, package project by Hadley.
What follows is a speed comparison of these three packages incorporating all the feedback from the manipulator folks. They found it informative, so Tal asked me to write it up as a reproducible example.
Disclaimer: This post is not intended to be a comprehensive review, but more of a “getting started guide”. If I did not mention an important tool or package I apologize, and invite readers to contribute in the comments.
Introduction
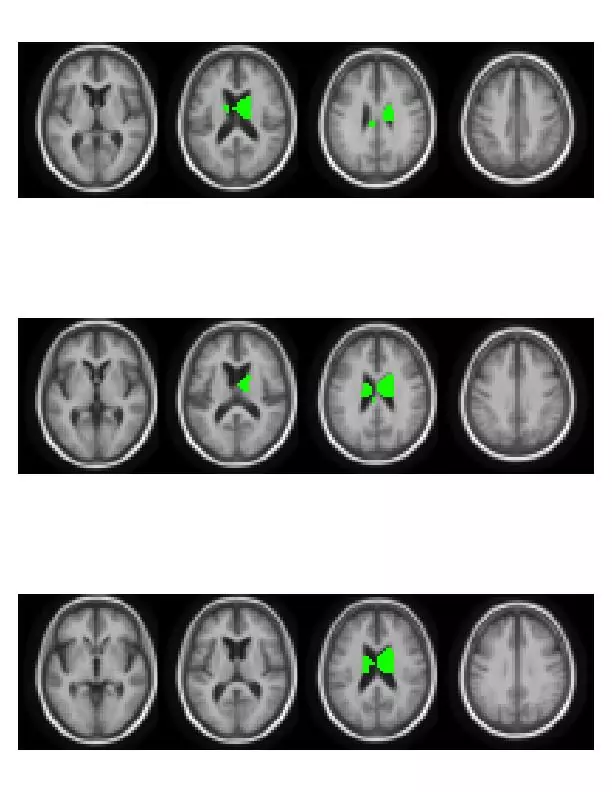
I have recently had the delight to participate in a “Brain Hackathon” organized as part of the OHBM2013 conference. Being supported by Amazon, the hackathon participants were provided with Amazon credit in order to promote the analysis using Amazon’s Web Services (AWS). We badly needed this computing power, as we had 14*109 p-values to compute in order to localize genetic associations in the brain leading to Figure 1.
Figure 1- Brain volumes significantly associated to genotype.
While imaging genetics is an interesting research topic, and the hackathon was a great idea by itself, it is the AWS I wish to present in this post. Starting with the conclusion:
Storing your data and analyzing it on the cloud, be it AWS, Azure, Rackspace or others, is a quantum leap in analysis capabilities. I fell in love with my new cloud powers and I strongly recommend all statisticians and data scientists get friendly with these services. I will also note that if statisticians do not embrace these new-found powers, we should not be surprised if data analysis becomes synonymous with Machine Learning and not with Statistics (if you have no idea what I am talking about, read this excellent post by Larry Wasserman).
As motivation for analysis in the cloud consider:
The ability to do your analysis from any device, be it a PC, tablet or even smartphone.
The ability to instantaneously augment your CPU and memory to any imaginable configuration just by clicking a menu. Then scaling down to save costs once you are done.
The ability to instantaneously switch between operating systems and system configurations.
The ability to launch hundreds of machines creating your own cluster, parallelizing your massive job, and then shutting it down once done.
Here is a quick FAQ before going into the setup stages.
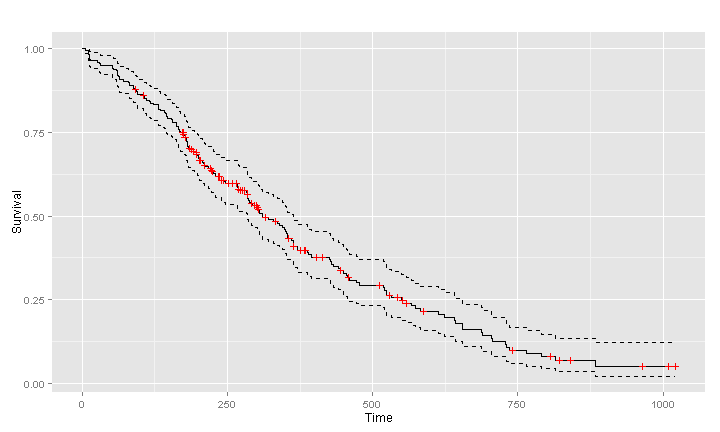
Currently I am doing my master thesis on multi-state models. Survival analysis was my favourite course in the masters program, partly because of the great survival package which is maintained by Terry Therneau. The only thing I am not so keen on are the default plots created by this package, by using plot.survfit. Although the plots are very easy to produce, they are not that attractive (as are most R default plots) and legends has to be added manually. I come across them all the time in the literature and wondered whether there was a better way to display survival. Since I was getting the grips of ggplot2 recently I decided to write my own function, with the same functionality as plot.survfitbut with a result that is much better looking. I stuck to the defaults of plot.survfit as much as possible, for instance by default plotting confidence intervals for single-stratum survival curves, but not for multi-stratum curves. Below you’ll find the code of the ggsurv function. Just as plot.survfit it only requires a fitted survival object to produce a default plot. We’ll use the lung data set from the survival package for illustration. First we load in the function to the console (see at the end of this post).
Once the function is loaded, we can get going, we use the lung data set from the survival package for illustration.
What are the top 100 (most downloaded) R packages in 2013? Thanks to the recent release of RStudio of their “0-cloud” CRAN log files (but without including downloads from the primary CRAN mirror or any of the 88 other CRAN mirrors), we can now answer this question (at least for the months of Jan till May)!
By relying on the nice code that Felix Schonbrodt recently wrote for tracking packages downloads, I have updated my installr R package with functions that enables the user to easily download and visualize the popularity of R packages over time. In this post I will share some nice plots and quick insights that can be made from this great data. The code for this analysis is given at the end of this post.
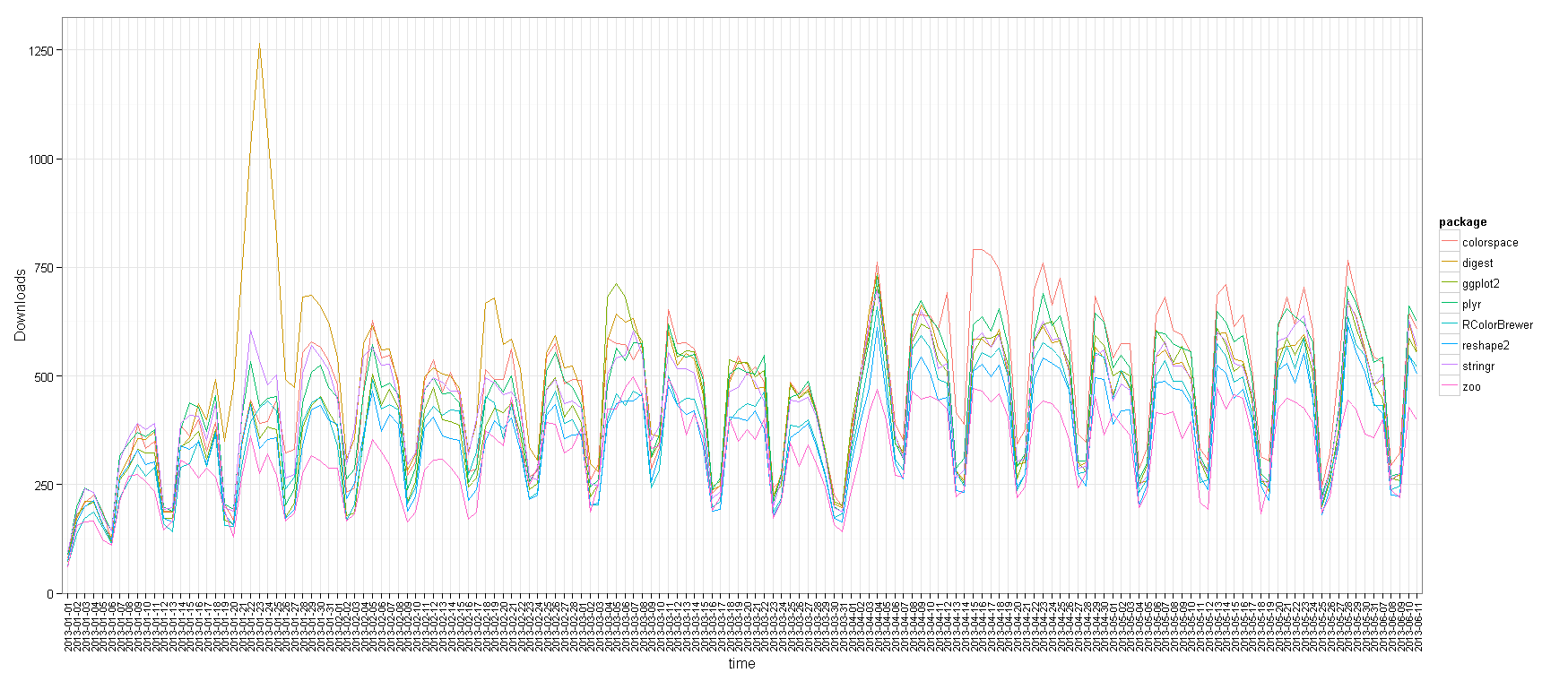
Top 8 most downloaded R packages – downloads over time
Let’s first have a look at the number of downloads per day for these 5 months, of the top 8 most downloaded packages (click the image for a larger version):
We can see the strong weekly seasonality of the downloads, with Saturday and Sunday having much fewer downloads than other days. This is not surprising since we know that the countries which uses R the most have these days as rest days (see James Cheshire’s world map of R users). It is also interesting to note how some packages had exceptional peaks on some dates. For example, I wonder what happened on January 23rd 2013 that the digest package suddenly got so many downloads, or that colorspace started getting more downloads from April 15th 2013.
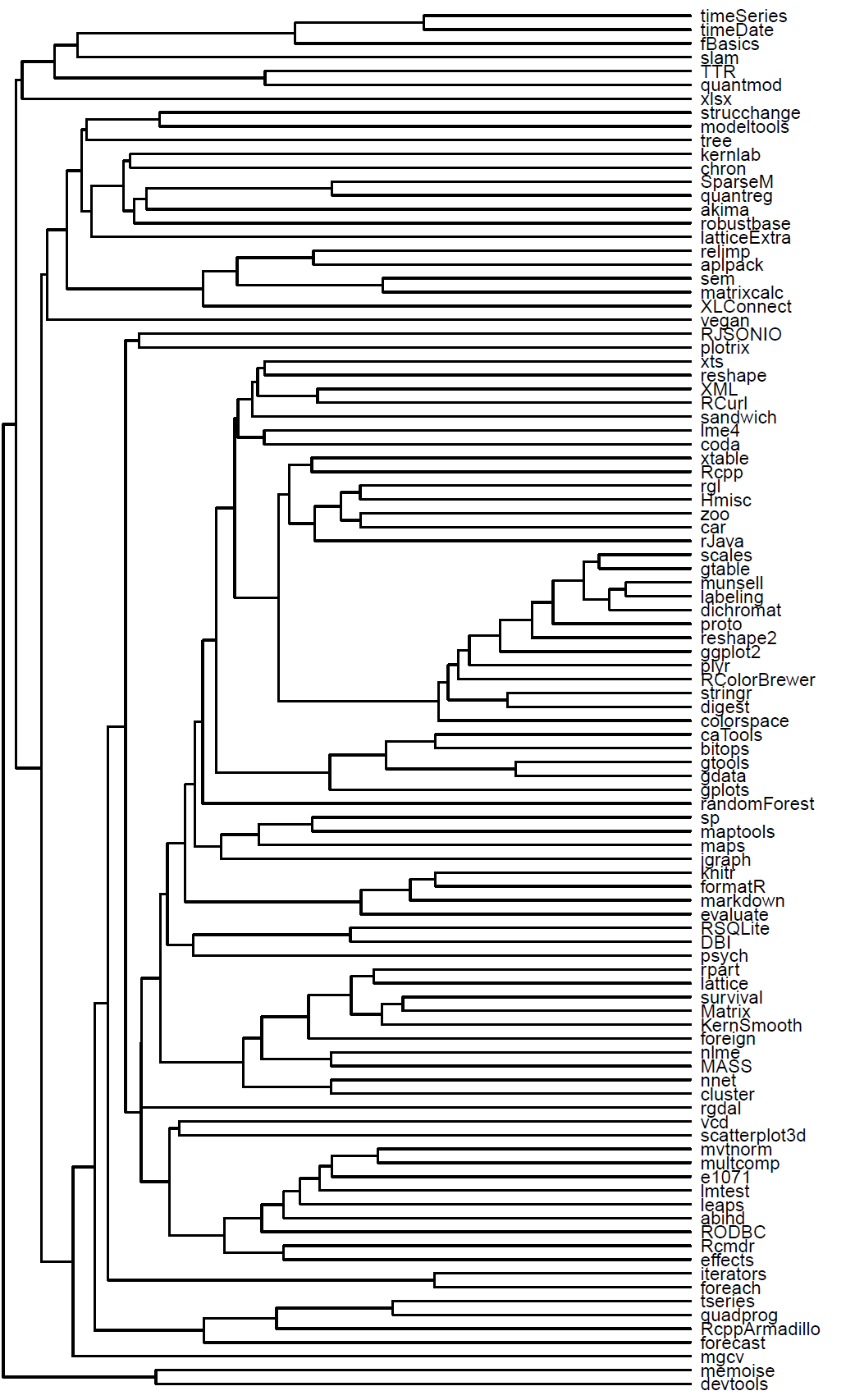
“Family tree” of the top 100 most downloaded R packages
We can extract from this data the top 100 most downloaded R packages. Moreover, we can create a matrix showing for each package which of our unique ids (censored IP addresses), has downloaded which package. Using this indicator matrix, we can thing of the “similarity” (or distance) between each two packages, and based on that we can create a hierarchical clustering of the packages – showing which packages “goes along” with one another.
With this analysis, you can locate package on the list which you often use, and then see which other packages are “related” to that package. If you don’t know that package – consider having a look at it – since other R users are clearly finding the two packages to be “of use”.
Such analysis can (and should!) be extended. For example, we can imagine creating a “suggest a package” feature based on this data, utilizing the package which you use, the OS that you use, and other parameters. But such coding is beyond the scope of this post.
Here is the “family tree” (dendrogram) of related packages:
To make it easier to navigate, here is a table with links to the top 100 R packages, and their links:
This is a guest article by Nina Zumel and John Mount, authors of the new book Practical Data Science with R. For readers of this blog, there is a 50% discount offthe “Practical Data Science with R” book, simply by using the code pdswrblo when reaching checkout (until the 30th this month). Here is the post:
Normalizing data by mean and standard deviation is most meaningful when the data distribution is roughly symmetric. In this article, based on chapter 4 of Practical Data Science with R, the authors show you a transformation that can make some distributions more symmetric.
The need for data transformation can depend on the modeling method that you plan to use. For linear and logistic regression, for example, you ideally want to make sure that the relationship between input variables and output variables is approximately linear, that the input variables are approximately normal in distribution, and that the output variable is constant variance (that is, the variance of the output variable is independent of the input variables). You may need to transform some of your input variables to better meet these assumptions.
In this article, we will look at some log transformations and when to use them.
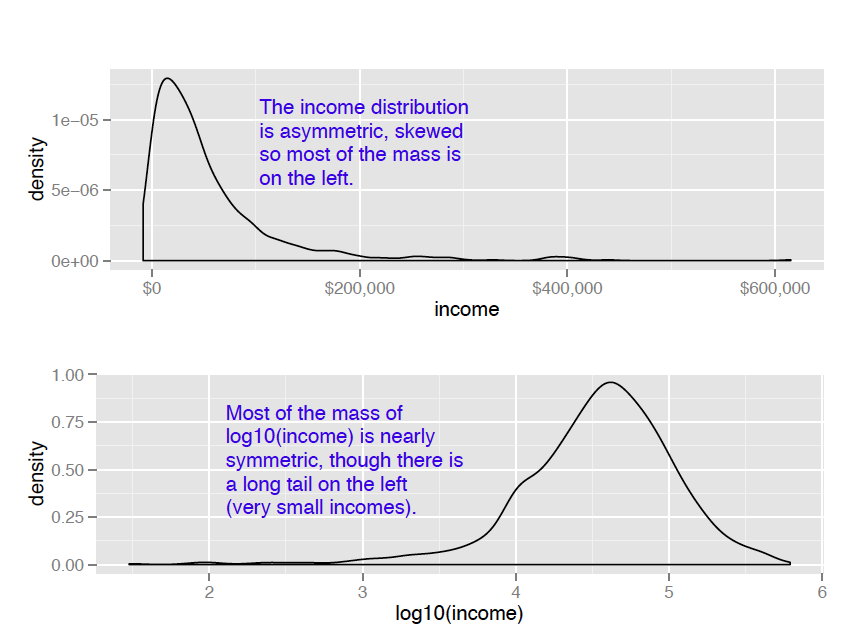
Monetary amounts—incomes, customer value, account or purchase sizes—are some of the most commonly encountered sources of skewed distributions in data science applications. In fact, as we discuss in Appendix B: Important Statistical Concepts, monetary amounts are often lognormally distributed—that is, the log of the data is normally distributed. This leads us to the idea that taking the log of the data can restore symmetry to it. We demonstrate this in figure 1.
Figure 1 A nearly lognormal distribution, and its log
For the purposes of modeling, which logarithm you use—natural logarithm, log base 10 or log base 2—is generally not critical. In regression, for example, the choice of logarithm affects the magnitude of the coefficient that corresponds to the logged variable, but it doesn’t affect the value of the outcome. I like to use log base 10 for monetary amounts, because orders of ten seem natural for money: $100, $1000, $10,000, and so on. The transformed data is easy to read.
An aside on graphing
The difference between using the ggplot layer scale_x_log10 on a densityplot of income and plotting a densityplot of log10(income) is primarily axis labeling. Using scale_x_log10 will label the x-axis in dollars amounts, rather than in logs.
It’s also generally a good idea to log transform data with values that range over several orders of magnitude. First, because modeling techniques often have a difficult time with very wide data ranges, and second, because such data often comes from multiplicative processes, so log units are in some sense more natural.
For example, when you are studying weight loss, the natural unit is often pounds or kilograms. If I weigh 150 pounds, and my friend weighs 200, we are both equally active, and we both go on the exact same restricted-calorie diet, then we will probably both lose about the same number of pounds—in other words, how much weight we lose doesn’t (to first order) depend on how much we weighed in the first place, only on calorie intake. This is an additive process.
On the other hand, if management gives everyone in the department a raise, it probably isn’t by giving everyone $5000 extra. Instead, everyone gets a 2 percent raise: how much extra money ends up in my paycheck depends on my initial salary. This is a multiplicative process, and the natural unit of measurement is percentage, not absolute dollars. Other examples of multiplicative processes: a change to an online retail site increases conversion (purchases) for each item by 2 percent (not by exactly two purchases); a change to a restaurant menu increases patronage every night by 5 percent (not by exactly five customers every night). When the process is multiplicative, log-transforming the process data can make modeling easier.
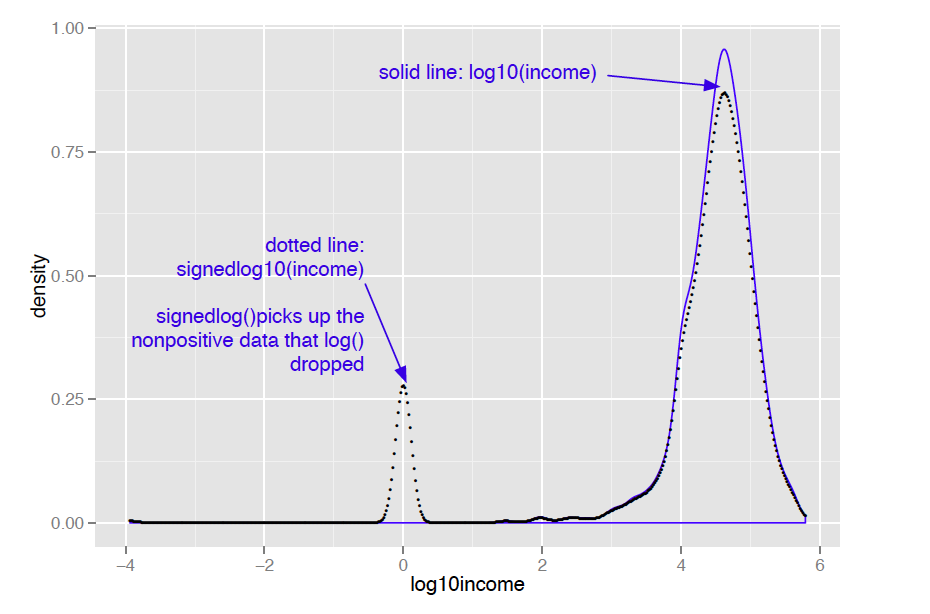
Of course, taking the logarithm only works if the data is non-negative. There are other transforms, such as arcsinh, that you can use to decrease data range if you have zero or negative values. I don’t like to use arcsinh, because I don’t find the values of the transformed data to be meaningful. In applications where the skewed data is monetary (like account balances or customer value), I instead use what I call a “signed logarithm”. A signed logarithm takes the logarithm of the absolute value of the variable and multiplies by the appropriate sign. Values with absolute value less than one are mapped to zero. The difference between log and signed log are shown in figure 2.
Figure 2 Signed log lets you visualize non-positive data on a logarithmic scale
Clearly this isn’t useful if values below unit magnitude are important. But with many monetary variables (in US currency), values less than a dollar aren’t much different from zero (or one), for all practical purposes. So, for example, mapping account balances that are less than a dollar to $1 (the equivalent every account always having a minimum balance of one dollar) is probably okay.
Once you’ve got the data suitably cleaned and transformed, you are almost ready to start the modeling stage.
Summary
At some point, you will have data that is as good quality as you can make it. You've fixed problems with missing data, and performed any needed transformations. You are ready to go on the modeling stage. Remember, though, that data science is an iterative process. You may discover during the modeling process that you have to do additional data cleaning or transformation.
R 3.0.1 (codename “Good Sport”) was released last week. As mentioned earlier by David, this version improves serialization performance with big objects, improves reliability for parallel programming and fixes a few minor bugs.
Upgrading to R 3.0.1
You can download the latest version from here. Or, if you are using windows, you can upgrade to the latest version using the installr package (also available on CRAN and github). Simply run the following code:
# installing/loading the package:
if(!require(installr)) {
install.packages("installr"); require(installr)} #load / install+load installr
updateR(to_checkMD5sums = FALSE) # the use of to_checkMD5sums is because of a slight bug in the MD5 file on R 3.0.1. Soon this should get resolved and you could go back to using updateR(), install.R() or the menu upgrade system.
I try to keep the installr package updated and useful. If you have any suggestions or remarks on the package, you’re invited to leave a comment below.
If you use the global library system (as I do), you can run the following in the new version of R:
A few hours ago Peter Dalgaard (of R Core Team) announced the release of R 3.0.0! Bellow you can read the changes in this release.
One of the features worth noticing is the introduction of long vectors to R 3.0.0. As David Smith recently wrote:
Although many people won’t notice the difference, the introduction of long vectors to R is in fact a significant upgrade, and required a lot of work behind-the-scenes to implement in the core R engine. It will allow data frames to exceed their current 2 billion row limit, and in general allow R to make better use of memory in systems with large amounts of RAM. Many thanks go to the R core team for making this improvement.
or wait for it to be mirrored at a CRAN site nearer to you. Binaries for various platforms will appear in due course (which often means it will be within the next 2-48 hours).
If you are running R on Ubuntu, you may wish to consult this post.
If you are running R on Windows, you can use the following code to quickly download and install the latest R version using the installr package:
# installing/loading the package:
if(!require(installr)) {
install.packages("installr"); require(installr)} #load / install+load installr
install.R(to_checkMD5sums = FALSE) # the use of to_checkMD5sums is because of a slight bug in the MD5 file on R 3.0.0. Soon this should get resolved and you could go back to using updateR()
Either way, all users should note that this new release requires that packages will need to be re-installed, which means that after you install the new R, you should run the following command in it:
update.packages(checkBuilt=TRUE)
(thank to Prof. Ripley for the above clarification, and the FAQ pointer)
Update (2019-08-17): to see a good solution for this problem, please go to this link. The solution in the post is old and while it still works, it is better to use the newer methods from the link.
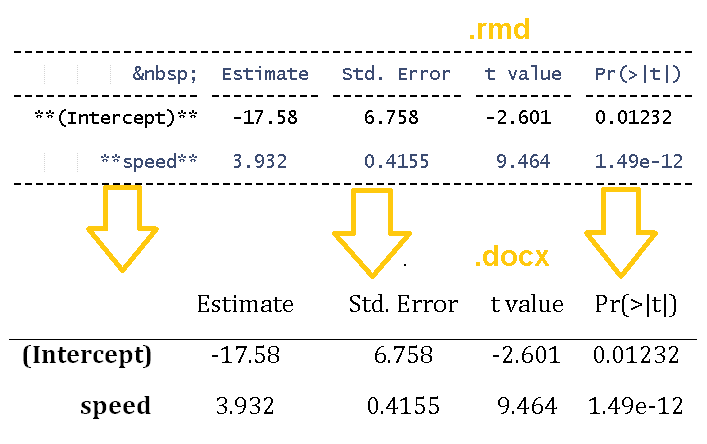
The problem: producing a Word (.docx) file of a statistical report created in R, with as little overhead as possible. The solution: combining R+knitr+rmarkdown+pander+pandoc (it is easier than it is spelled).
If you get what this post is about, just jump to the “Solution: the workflow” section.
Preface: why is this a problem (/still)
Before turning to the solution, let’s address two preliminary questions:
Q: Why is it important to be able to create report in Word from R?
A: Because many researchers we may work with are used to working with Word for editing their text, tracking changes and merging edits between different authors, and copy-pasting text/tables/images from various sources. This means that a report produced as a PDF file is less useful for collaborating with less-tech-savvy researchers (copying text or tables from PDF is not fun). Even exchanging HTML files may appear somewhat awkward to fellow researchers. Continue reading “Writing a MS-Word document using R (with as little overhead as possible)”