I’m excited to announce that heatmaply version 1.0.0 has been published to CRAN! (getting started vignette is available here)
What is heatmaply?
heatmaply is an R package for easily creating interactive cluster heatmaps that can be shared online as a stand-alone HTML file. Interactivity includes a tooltip display of values when hovering over cells, as well as the ability to zoom in to specific sections of the figure from the data matrix, the side dendrograms, or annotated labels.
The package aims to be compatible with gplots::heatmap.2 so you could take code written for it and just change the heatmap.2 command to be heatmaply, and get the interactive version of the plot (although with slightly different, improved, defaults for colors and dendrogram ordering). Thanks to the synergistic relationship between heatmaply and other R packages, the user is empowered by a refined control over the statistical and visual aspects of the heatmap layout.
What makes heatmaply great?
The change from version 0.16.0 to version 1.0.0 is to indicate the maturity of the package. It is to reflect the following facts:
Summary:heatmaply is an R package for easily creating interactive cluster heatmaps that can be shared online as a stand-alone HTML file. Interactivity includes a tooltip display of values when hovering over cells, as well as the ability to zoom in to specific sections of the figure from the data matrix, the side dendrograms, or annotated labels. Thanks to the synergistic relationship between heatmaply and other R packages, the user is empowered by a refined control over the statistical and visual aspects of the heatmap layout.
Availability: The heatmaply package is available under the GPL-2 Open Source license. It comes with a detailed vignette, and is freely available from: http://cran.r-project.org/package=heatmaply
ggplot2 has become the standard of plotting in R for many users. New users, however, may find the learning curve steep at first, and more experienced users may find it challenging to keep track of all the options (especially in the theme!).
ggedit is a package that helps users bridge the gap between making a plot and getting all of those pesky plot aesthetics just right, all while keeping everything portable for further research and collaboration.
ggedit is powered by a Shiny gadget where the user inputs a ggplot plot object or a list of ggplot objects. You can run ggedit directly from the console from the Addin menu within RStudio.
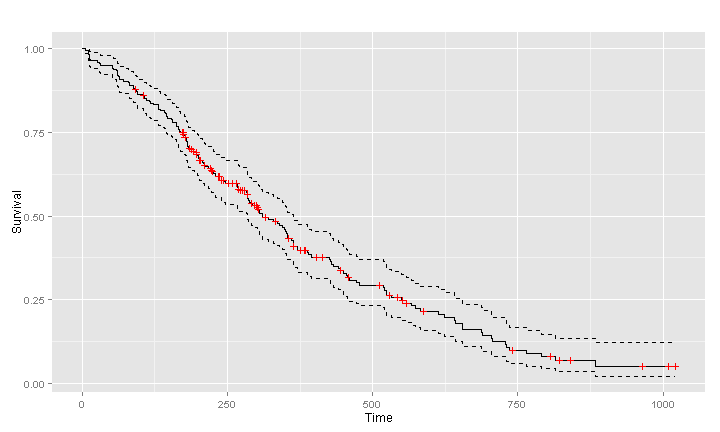
Currently I am doing my master thesis on multi-state models. Survival analysis was my favourite course in the masters program, partly because of the great survival package which is maintained by Terry Therneau. The only thing I am not so keen on are the default plots created by this package, by using plot.survfit. Although the plots are very easy to produce, they are not that attractive (as are most R default plots) and legends has to be added manually. I come across them all the time in the literature and wondered whether there was a better way to display survival. Since I was getting the grips of ggplot2 recently I decided to write my own function, with the same functionality as plot.survfitbut with a result that is much better looking. I stuck to the defaults of plot.survfit as much as possible, for instance by default plotting confidence intervals for single-stratum survival curves, but not for multi-stratum curves. Below you’ll find the code of the ggsurv function. Just as plot.survfit it only requires a fitted survival object to produce a default plot. We’ll use the lung data set from the survival package for illustration. First we load in the function to the console (see at the end of this post).
Once the function is loaded, we can get going, we use the lung data set from the survival package for illustration.
The followings introductory post is intended for new users of R. It deals with interactive visualization using R through the iplots package.
This is a guest article by Dr. Robert I. Kabacoff, the founder of (one of) the first online R tutorials websites: Quick-R. Kabacoff has recently published the book ”R in Action“, providing a detailed walk-through for the R language based on various examples for illustrating R’s features (data manipulation, statistical methods, graphics, and so on…). In previous guest posts by Kabacoff we introduced data.frame objects in R and dealt with the Aggregation and Restructuring of data (using base R functions and the reshape package).
For readers of this blog, there is a 38% discount off the “R in Action” book (as well as all other eBooks, pBooks and MEAPs at Manning publishing house), simply by using the code rblogg38 when reaching checkout.
Let us now talk about Interactive Graphics with the iplots Package:
Interactive Graphics with the iplots Package
The base installation of R provides limited interactivity with graphs. You can modify graphs by issuing additional program statements, but there’s little that you can do to modify them or gather new information from them using the mouse. However, there are contributed packages that greatly enhance your ability to interact with the graphs you create—playwith, latticist, iplots, and rggobi. In this article, we’ll focus on functions provided by the iplots package. Be sure to install it before first use.
While playwith and latticist allow you to interact with a single graph, the iplots package takes interaction in a different direction. This package provides interactive mosaic plots, bar plots, box plots, parallel plots, scatter plots, and histograms that can be linked together and color brushed. This means that you can select and identify observations using the mouse, and highlighting observations in one graph will automatically highlight the same observations in all other open graphs. You can also use the mouse to obtain information about graphic objects such as points, bars, lines, and box plots.
The iplots package is implemented through Java and the primary functions are listed in table 1.
Table 1 iplot functions
Function
Description
ibar()
Interactive bar chart
ibox()
Interactive box plot
ihist()
Interactive histogram
imap()
Interactive map
imosaic()
Interactive mosaic plot
ipcp()
Interactive parallel coordinates plot
iplot()
Interactive scatter plot
To understand how iplots works, execute the code provided in listing 1.
Six windows containing graphs will open. Rearrange them on the desktop so that each is visible (each can be resized if necessary). A portion of the display is provided in figure 1.
Figure 1 An iplots demonstration created by listing 1. Only four of the six windows are displayed to save room. In these graphs, the user has clicked on the three-gear bar in the bar chart window.
Now try the following:
Click on the three-gear bar in the Barchart (gears) window. The bar will turn red. In addition, all cars with three-gear engines will be highlighted in the other graph windows.
Mouse down and drag to select a rectangular region of points in the Scatter plot (wt vs mpg) window. These points will be highlighted and the corresponding observations in every other graph window will also turn red.
Hold down the Ctrl key and move the mouse pointer over a point, bar, box plot, or line in one of the graphs. Details about that object will appear in a pop-up window.
Right-click on any object and note the options that are offered in the context menu. For example, you can right-click on the Boxplot (mpg) window and change the graph to a parallel coordinates plot (PCP).
You can drag to select more than one object (point, bar, and so on) or use Shift-click to select noncontiguous objects. Try selecting both the three- and five-gear bars in the Barchart (gears) window.
The functions in the iplots package allow you to explore the variable distributions and relationships among variables in subgroups of observations that you select interactively. This can provide insights that would be difficult and time-consuming to obtain in other ways. For more information on the iplots package, visit the project website at http://rosuda.org/iplots/.
Summary
In this article, we explored one of the several packages for dynamically interacting with graphs, iplots. This package allows you to interact directly with data in graphs, leading to a greater intimacy with your data and expanded opportunities for developing insights.
This article first appeared as chapter 16.4.4 from the “R in action“ book, and is published with permission from Manning publishing house. Other books in this serious which you might be interested in are (see the beginning of this post for a discount code):
A Bernoulli process is a sequence of Bernoulli trials (the realization of n binary random variables), taking two values (0/1, Heads/Tails, Boy/Girl, etc…). It is often used in teaching introductory probability/statistics classes about the binomial distribution. When visualizing a Bernoulli process, it is common to use a binary tree diagram in order to show the […]
A Bernoulli process is a sequence of Bernoulli trials (the realization of n binary random variables), taking two values (0/1, Heads/Tails, Boy/Girl, etc…). It is often used in teaching introductory probability/statistics classes about the binomial distribution.
When visualizing a Bernoulli process, it is common to use a binary tree diagram in order to show the progression of the process, as well as the various consequences of the trial. We might also include the number of “successes”, and the probability for reaching a specific terminal node.
I wanted to be able to create such a diagram using R. For this purpose I composed some code which uses the {diagram} R package. The final function should allow one to create different sizes of diagrams, while allowing flexibility with regards to the text which is used in the tree.
Here is an example of the simplest use of the function:
source("https://www.r-statistics.com/wp-content/uploads/2011/11/binary.tree_.for_.binomial.game_.r.txt") # loading the function
binary.tree.for.binomial.game(2) # creating a tree for B(2,0.5)
The resulting diagram will look like this:
The same can be done for creating larger trees. For example, here is the code for a 4 stage Bernoulli process:
source("https://www.r-statistics.com/wp-content/uploads/2011/11/binary.tree_.for_.binomial.game_.r.txt") # loading the function
binary.tree.for.binomial.game(4) # creating a tree for B(4,0.5)
The resulting diagram will look like this:
The function can also be tweaked in order to describe a more specific story. For example, the following code describes a 3 stage Bernoulli process where an unfair coin is tossed 3 times (with probability of it giving heads being 0.8):
2016-05-28 update: I strongly recommend reading the comment by Leland Wilkinson. In summary, “beeswarm” plots are not recommended as they often create visual artifacts that distracts from the estimated density of the observations.
(The image above is called a “Beeswarm Boxplot” , the code for producing this image is provided at the end of this post)
The above plot is implemented under different names in different softwares. This “Scatter Dot Beeswarm Box Violin – plot” (in the lack of an agreed upon term) is a one-dimensional scatter plot which is like “stripchart”, but with closely-packed, non-overlapping points; the positions of the points are corresponding to the frequency in a similar way as the violin-plot. The plot can be superimposed with a boxplot to give a very rich description of the underlaying distribution.
This plot has been implemented in various statistical packages, in this post I will list the few I came by so far. And if you know of an implementation I’ve missed please tell me about it in the comments.
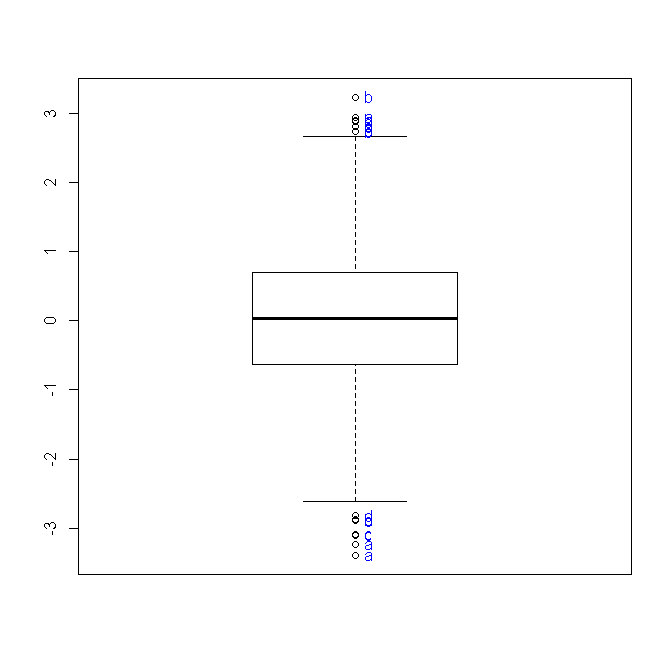
In this post I offer an alternative function for boxplot, which will enable you to label outlier observations while handling complex uses of boxplot.
In this post I present a function that helps to label outlier observations When plotting a boxplot using R.
An outlier is an observation that is numerically distant from the rest of the data. When reviewing a boxplot, an outlier is defined as a data point that is located outside the fences (“whiskers”) of the boxplot (e.g: outside 1.5 times the interquartile range above the upper quartile and bellow the lower quartile).
Identifying these points in R is very simply when dealing with only one boxplot and a few outliers. That can easily be done using the “identify” function in R. For example, running the code bellow will plot a boxplot of a hundred observation sampled from a normal distribution, and will then enable you to pick the outlier point and have it’s label (in this case, that number id) plotted beside the point:
set.seed(482)
y <- rnorm(100)
boxplot(y)
identify(rep(1, length(y)), y, labels = seq_along(y))
However, this solution is not scalable when dealing with:
Many outliers
Overlapping data-points, and
Multiple boxplots in the same graphic window
For such cases I recently wrote the function "boxplot.with.outlier.label" (which you can download from here). This function will plot operates in a similar way as "boxplot" (formula) does, with the added option of defining "label_name". When outliers are presented, the function will then progress to mark all the outliers using the label_name variable. This function can handle interaction terms and will also try to space the labels so that they won't overlap (my thanks goes to Greg Snow for his function "spread.labs" from the {TeachingDemos} package, and helpful comments in the R-help mailing list).
Here is some example code you can try out for yourself:
source("https://raw.githubusercontent.com/talgalili/R-code-snippets/master/boxplot.with.outlier.label.r") # Load the function
# sample some points and labels for us:
set.seed(492)
y <- rnorm(2000)
x1 <- sample(letters[1:2], 2000,T)
x2 <- sample(letters[1:2], 2000,T)
lab_y <- sample(letters[1:4], 2000,T)
# plot a boxplot with interactions:
boxplot.with.outlier.label(y~x2*x1, lab_y)
Here is the resulting graph:
You can also have a try and run the following code to see how it handles simpler cases:
# plot a boxplot without interactions:
boxplot.with.outlier.label(y~x1, lab_y, ylim = c(-5,5))
# plot a boxplot of y only
boxplot.with.outlier.label(y, lab_y, ylim = c(-5,5))
boxplot.with.outlier.label(y, lab_y, spread_text = F) # here the labels will overlap (because I turned spread_text off)
Here is the output of the last example, showing how the plot looks when we allow for the text to overlap (we would often prefer to NOT allow it).
Regarding package dependencies: notice that this function requires you to first install the packages {TeachingDemos} (by Greg Snow) and {plyr} (by Hadley Wickham)
Updates: 19.04.2011 - I've added support to the boxplot "names" and "at" parameters.
You are very much invited to leave your comments if you find a bug, think of ways to improve the function, or simply enjoyed it and would like to share it with me.
Earlier today, Ian Fwllows has announced the release of Deducer 0.4-2 and DeducerExtras 1.2 to CRAN (I copy his announcement here): Deducer 0.4-2 contains a few bug fixes, and an interface to the iplots package. With the new iplots interface it is now possible to do interactive plots with Deducer. An introductory example screen cast (by Ian) is available on the tube:
DeducerExtras 1.2 contains a few new dialogs including ‘load data from package’, and ‘t-test power’.
Additionally, a new Windows R/JGR/Deducer installer is available which installs R-2.12.0, JGR with it’s launcher, Deducer, DeducerExtras, and DeducerPlugInScaling. It is available on the Deducer website: http://www.deducer.org/pmwiki/pmwiki.php?n=Main.WindowsInstallation
Following today’s announcement, by Ian Fellows, regarding the release of the new version of Deducer (0.4) offering a strong support for ggplot2 using a GUI plot builder, Ian also sent an e-mail where he shows how to create a rose plot using the new ggplot2 GUI included in the latest version of Deducer. After the template is made, the plot can be generated with 4 clicks of the mouse.
Here is a video tutorial (Ian published) to show how this can be used:







")